朴素贝叶斯分类器
题目链接:Naive Bayes
项目链接:Spam Filter
第一步:确定特征属性,建立训练数据表
假设字母表中有 V 个单词,训练文本(train-feature.txt)中共有 E 个邮件。
从训练文本中提取特征,建立词袋模型,也就是一个 E × V 的矩阵(训练数据表)。该矩阵的每一行代表一个邮件,每一列代表一个单词。矩阵中第 i 行第 j 列的数据代表第 i 封邮件中含有序号为 j 的单词的数量。
第二步:根据样本训练模型
为了建立朴素贝叶斯模型,需要根据训练数据表计算出模型的参数:

注:如果某些单词在训练集中没出现过,那么计算该单词的出现概率时会得到零概率。这显然是不合理的,因为某个单词没在训练集中出现不代表它就不可能在其它邮件中出现。为了处理零概率问题,此处使用了
拉普拉斯平滑,即在分母加上字母表的单词数,并在分子加 1。
第三步:将贝叶斯模型应用于邮件分类
邮件只有两种类别:垃圾邮件和非垃圾邮件,分别记为 y = 1 和 y = 0。
假设现在有一封测试邮件,邮件中出现了单词 a、单词 b、……、单词 n。现在需要根据第二步得出的贝叶斯模型来判断该邮件是不是垃圾邮件。
首先写出数学公式:

为了判断某个邮件是不是垃圾邮件,需要比较这两个概率的大小。注意到两式的分母相同,所以只需比较分子的大小。又考虑到用程序计算时可能会出现溢出的问题,可以对分子的对数进行比较,也就是比较以下两个值:

如果第一个值大,则判断该邮件的垃圾邮件;否则判断该邮件是非垃圾邮件。
具体代码
from collections import namedtuple
from math import log10
# Naive Bayes Model
Model = namedtuple('Model', ['prob_spam', 'prob_word_spam', 'prob_word_ham'])
# Spam Label
SPAM = 1
# Ham Label
HAM = 0
def train(train_feature_filename, train_label_filename, train_email_num, word_num):
"""Train the model"""
# load the features into a full matrix (email_id | word_id | occurrence)
train_matrix = load_feature(train_feature_filename, train_email_num, word_num)
# load the labels into a list (email_id => label)
train_labels = load_labels(train_label_filename)
# filter email ids with labels
spam_email_ids = []
ham_email_ids = []
for i in range(train_email_num):
if train_labels[i] == SPAM:
spam_email_ids.append(i)
else:
ham_email_ids.append(i)
# P(spam)
# = number-of-spam / number-of-email
prob_spam = len(spam_email_ids) / train_email_num
# P(word[i] | spam)
# = (number-of-word[i]-in-spam + 1) / (number-of-words-in-spam + number-of-words)
spam_word_count = [0 for i in range(word_num)]
spam_word_num = 0
for spam_email_id in spam_email_ids:
spam_word_occurs = train_matrix[spam_email_id]
for word_id, word_occur in enumerate(spam_word_occurs):
spam_word_count[word_id] += word_occur
spam_word_num += word_occur
prob_word_spam = []
for word_id in range(word_num):
prob_word_spam.append((spam_word_count[word_id] + 1) / (spam_word_num + word_num))
# P(word[i] | ham)
# = (number-of-word[i]-in-ham + 1) / (number-of-words-in-ham + number-of-words)
ham_word_count = [0 for i in range(word_num)]
ham_word_num = 0
for ham_email_id in ham_email_ids:
ham_word_occurs = train_matrix[ham_email_id]
for word_id, word_occur in enumerate(ham_word_occurs):
ham_word_count[word_id] += word_occur
ham_word_num += word_occur
prob_word_ham = []
for word_id in range(word_num):
prob_word_ham.append((ham_word_count[word_id] + 1) / (ham_word_num + word_num))
# return model
return Model(prob_spam, prob_word_spam, prob_word_ham)
def test(model, test_feature_filename, test_label_filename, test_email_num, test_word_num):
"""Make predictions on test data"""
# load the features into a full matrix (email_id | word_id | occurrence)
test_matrix = load_feature(test_feature_filename, test_email_num, test_word_num)
# load the labels into a list (email_id => label)
test_labels = load_labels(test_label_filename)
# predict each email in test data
true_spam = 0
false_spam = 0
true_ham = 0
false_ham = 0
for email_id in range(test_email_num):
word_occurs = test_matrix[email_id]
predict_result = predict(model, word_occurs)
if predict_result == SPAM and test_labels[email_id] == SPAM:
true_spam += 1
elif predict_result == SPAM and test_labels[email_id] == HAM:
false_spam += 1
elif predict_result == HAM and test_labels[email_id] == HAM:
true_ham += 1
else:
false_ham += 1
accuracy_score = (true_spam + true_ham) / test_email_num
precision_score = true_spam / (true_spam + false_spam)
recall_score = true_spam / (true_spam + false_ham)
f1_score = (2 * precision_score * recall_score) / (precision_score + recall_score)
# print result
print("Accuracy score: " + str(accuracy_score))
print("Precision score: " + str(precision_score))
print("Recall score: " + str(recall_score))
print("F1 score: " + str(f1_score))
def predict(model, word_occurs):
"""Predict whether an email is spam or not"""
# ids of words that appear in this email
appear_word_ids = [word_id for word_id, word_occur in enumerate(word_occurs) if word_occur > 0]
# P(spam | appear-words) => spam?
# math: P(spam) * P(appear-word[0] | spam) * P(appear-word[1] | spam) * ... * P(appear-word[n] | spam)
# calculate: log(P(spam)) + log(P(appear-word[0] | spam)) + ... + log(P(appear-word[n] | spam))
spam_score = log10(model.prob_spam)
for appear_word_id in appear_word_ids:
spam_score += log10(model.prob_word_spam[appear_word_id])
# P(ham | appear-words) => ham?
# math: P(ham) * P(appear-word[0] | ham) * P(appear-word[1] | ham) * ... * P(appear-word[n] | ham)
# calculate: log(P(ham)) + log(P(appear-word[0] | ham)) + ... + log(P(appear-word[n] | ham))
ham_score = log10(1 - model.prob_spam)
for appear_word_id in appear_word_ids:
ham_score += log10(model.prob_word_ham[appear_word_id])
# Compare the two scores and make a decision about whether this email is spam
if spam_score > ham_score:
return SPAM
else:
return HAM
def load_feature(feature_filename, email_num, word_num):
"""Load the features into a full matrix"""
matrix = [[0 for i in range(word_num)] for j in range(email_num)]
with open(feature_filename, 'r', encoding='utf-8') as fp:
for line in fp:
# email_id | word_id | occurrence
line_data = line.split()
email_id = int(line_data[0]) - 1
word_id = int(line_data[1]) - 1
occur = int(line_data[2])
matrix[email_id][word_id] += occur
return matrix
def load_labels(label_filename):
"""Load the labels into a list (email_id => label)"""
labels = []
with open(label_filename, 'r', encoding='utf-8') as fp:
for line in fp:
labels.append(int(line))
return labels
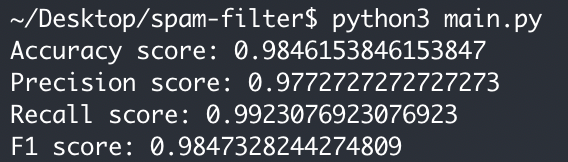
评测结果
使用题目中提供的数据进行测试:
import bayes
def main():
# the number of words in the dictionary
word_num = 2500
# file that contains features of emails to be used in training
train_feature_filename = "./data/train-features.txt"
# file that contains labels of emails to be used in training
train_label_filename = "./data/train-labels.txt"
# the number of training emails
train_email_num = 700
# file that contains features of emails to be used in testing
test_feature_filename = "./data/test-features.txt"
# file that contains labels of emails to be used in testing
test_label_filename = "./data/test-labels.txt"
# the number of testing emails
test_email_num = 260
# train naive bayes model
model = bayes.train(train_feature_filename, train_label_filename, train_email_num, word_num)
# make predictions on test data
bayes.test(model, test_feature_filename, test_label_filename, test_email_num, word_num)
if __name__ == "__main__":
main()
测试结果如下: